The AI Paper Proofers
Chatbots and large language models are being used to fact-check scientific work, but how effective are they?
by Nicola Jones
September 16, 2025
Last year, reports went viral warning that black plastic cooking implements could contain worrying levels of cancer-linked flame retardants. Droves of people threw their spatulas away. But it turns out that while cooking with plastic is undoubtedly a dubious idea, this
particular research paper contained an important math error. The authors accidentally
dropped a factor of 10 when converting units for the recommended safety limit of the chemicals, making the plastic leaching values seem much, much closer to the threshold than they really were.
The error was spotted by Joe Schwarcz, a chemist and the director of the Office for Science and Society at McGill University, in Montreal, Quebec, who noted that the slip didn't change the paper's main conclusion that these kitchen items contain worrying chemicals. The event prompted some to wonder whether artificial intelligence (AI) chatbots could be doing the job of checking papers for simple mistakes faster and more thoroughly than humans. At least two AI experts,
Ethan Mollick and
Nick Gibb, posited on social media that a simple prompt, like asking ChatGPT to "carefully check the math in this paper," could sometimes (but not always) find this particular flaw. When Steve Newman, an entrepreneur based in San Francisco, California, posted that someone should try this at scale, the suggestion went
viral.
Thus Newman's
Black Spatula Project was born: a community effort to explore whether chatbots, and large language models (LLMs) in general, can be helpful and effective paper proofers.
There are things that can be done without AI. You should not go: I have a problem, let's try to solve it with an LLM.
- Cyril Labbé
The idea of using automated tools to help check manuscripts for errors isn't new. At least one non-AI automated tool for checking statistics has been around for more than a decade. For years, several commercial AI-powered systems have existed to specifically look for the misuse of images and graphs. Other AI systems exist for investigating, for example, whether your paper meets a journal's publishing requirements, or whether a paper cites retracted research. Such systems can help to root out anything from typos to fraud, and can be used by researchers on their own papers before submission, by publishers during review, or by readers after publication.
What Newman is investigating is whether the increasing power of LLM-powered chatbots can provide a more comprehensive, one-stop shop for checking a paper, especially for honest mistakes, spotting all kinds of errors in math, coding, statistics or logic. Such a system would also yield data to investigate what sorts of errors are most prevalent in which fields,
Newman adds.
Together, such tools could in theory provide an AI review to complement peer review. This idea offers great hope for science, but could also create new problems. Newman says his Black Spatula project quickly spiraled into being far more complicated than he had originally imagined: "Some of the questions that have arisen are almost philosophical in nature."
The research literature is thought to be riddled with problems (see "
Do We Still Need Scientific Journals?"). Quantifying the scale of the issue is hard. One metric is whether a study is reproducible; if not, that may hint that the results are flawed. One infamous
2015 study of 100 psychology studies published across three journals in a single year found that more than half failed a reproducibility test. Just this year, a coalition focusing on three biomedical research methods
found that more than half of Brazilian biomedical studies could not be replicated.
Another concerning statistic is the number of retractions. The Retraction Watch database now catalogs more than 60,000 retractions. At least 0.2% of the more than 3 million papers published each year are retracted;
Ivan Oransky, co-founder of that project, has
estimated that it should be about 2%.
Experimenting with Peer Review
Online science platform Research Hub is trialing 'AI editors' and 'AI scientists' to conduct peer review, and, along with the journals Critical Care Medicine and Biology Open, also trialing paying human peer reviews.
Full Podcast
The scale of the problem makes automation desirable. More than a decade ago, meta-scientist Michèle Nuijten at Tilburg University in the Netherlands was concerned with the
misuse of statistics, specifically in her own field of psychology. So, she co-invented a simple, non-AI program called
statcheck to check whether the three values typically reported in psychology papers match up with each other (namely: the sample size, the test statistic, and the 'p value', which measures whether a result is due to chance). "It's kind of a spellchecker for statistics," says Nuijten. To their surprise, in a
2015 scan of more than 30,000 papers using statcheck, she and her colleagues found about 1 in 8 papers made errors big enough to possibly alter the statistical conclusion.
Today, statcheck is a free, open source
tool that anyone can use to check a paper (and other similar tools exist, like the
GRIM test). But they only work for psychology and a few fields that have a very specific reporting style for their statistics.
AI provides a way around this restriction: a chatbot can extract all kinds of numbers and perform all kinds of calculations, as witnessed by the black spatula paper example. But while current versions of AI chatbots can perform
stunningly well in high-level math, they also still, sometimes,
get very simple math wrong. Developers are working to fix this problem, but it's complicated, often involving getting chatbots to follow an energy-intensive chain-of-thought process or using multiple bots to check each other's work. As a result, using AI to check simple math is "kind of like cracking a nut with a sledgehammer," says Nuijten.
Perhaps the largest-scale problem in the literature is the publication of research by papermills: poor-quality or fraudulent research published to push an agenda. One
analysis found that 1.5-2% of all scientific papers published in 2022, and 3% of biology and medicine papers, bore telltale signs of coming from a papermill.
Several tools have arisen over the past decades to push back this rising tide. Computer scientists Guillaume Cabanac at the University of Toulouse, in France, and Cyril Labbé at the University of Grenoble, also in France, for example, co-invented the non-AI
Problematic Paper Screener, a free online tool that hunts for a host of issues in papers, including whether they use a poor cell line for a biological experiment, incorrectly describe a reagent, cite a retracted paper, or bear the fingerprints of having been made by a fake-paper generator like SCIgen or Mathgen (tools that were originally invented to help test whether conferences were legitimately reviewing their submissions). It also finds examples of "tortured phrases" produced by pre-chatbot 'automatic paraphrasers': like "informational collections" rather than "datasets," for example, or "fake neural organizations" instead of "artificial neural networks."
The screener is continually being used for checking scientific literature and has so far flagged more than 900,000 issues (the vast majority of which are papers citing retracted works), including 20,000 papers using tortured phrases (6000 of them in IEEE publications). "This is a terrific tool," says Oransky. In February 2024, for example, Cabanac
flagged a large batch of 48 or more suspicious physics papers all published in the journal
Optical and Quantum Electronics. After investigation, the journal
retracted more than 200 papers.
The Problematic Paper Screener doesn't need AI to do its work, and that makes it less energy intensive and more transparent than an LLM-based system might be. "There are things that can be done without AI," says Labbé. "You should not go: I have a problem, let's try to solve it with an LLM." Oransky agrees: "A lot happened before people got really excited about AI," he says. "I don't like to see people get distracted by the latest shiny object and forget about the fundamentals and good-old-fashioned techniques."
If you have these models deciding if things are problematic, they might reinforce certain biases, such as flagging papers more from certain countries.
- Michèle Nuijten
Chatbots, of course, can
write even more convincing but fake papers. The Problematic Paper Screener cannot detect chatbot-generated text, but Labbé notes that a lot of AI-assisted text writing is harmless, used to save time or correct poor grammar. Some researchers have seen
worrying signs that chatbots could be behind an increase in formulaic and misleading biomedical papers, but Oransky says there is no sign in the Retraction Watch dataset that generative AI has created a boom in fake papers.
The Problematic Paper Screener has now been rolled into a
tool produced by the UK-based company
Signals (part of Research Signals Limited), which similarly hunts for red flags in papers. Company co-founder Elliott Lumb says says several publishers use or have trialed their systems to help screen manuscript submissions prior to publication, including the UK's Institute of Physics (IOP) Publishing.
Signals was launched in early 2024 with a variety of non-AI algorithms that hunt down specific signals of errors or dubious content in papers. At the time, says Lumb, "some people were using AI in this space. They were using it very much as a black box; it was about putting in a manuscript and it gave you 'red' or 'green' for 'bad' or 'good.'" That did not appeal to Lumb, as it seemed too non-transparent and prone to errors. But this July the company launched '
Sleuth AI,' a chatbot-powered interactive assistant that sits alongside all of Signal's non-AI checks, helping to flag "anything unusual" in a given paper. For example, it can quickly highlight irrelevant content or note inconsistencies in how data is presented. "We are developing quickly," says Lumb, who expects to turn the more reliable and useful AI prompts into official 'signals' in their system.
Other systems, too, have benefited from AI, such as those that help hunt for errors in images. Image manipulation—accidental or intentional—can take various forms: data might be recycled between different graphs, for example, photos of cell cultures might be reused (rotated or cropped) to purportedly illustrate different experiments, or images of 'Western blots' used to detect proteins might be manipulated. Attuned science sleuths can spot such problems by eye: in a
2016 study, consultant Elisabeth Bik and colleagues found imagery problems in 4% of the papers she analyzed. But unless you have a photographic memory, ramping this up benefits from AI. Commercial systems including Imagetwin, ImaCheck and Proofig have arisen to do just this. The
Science family of journals has been
using Proofig to screen all its submissions since January 2024, and
has said that it has caught many mistakes.
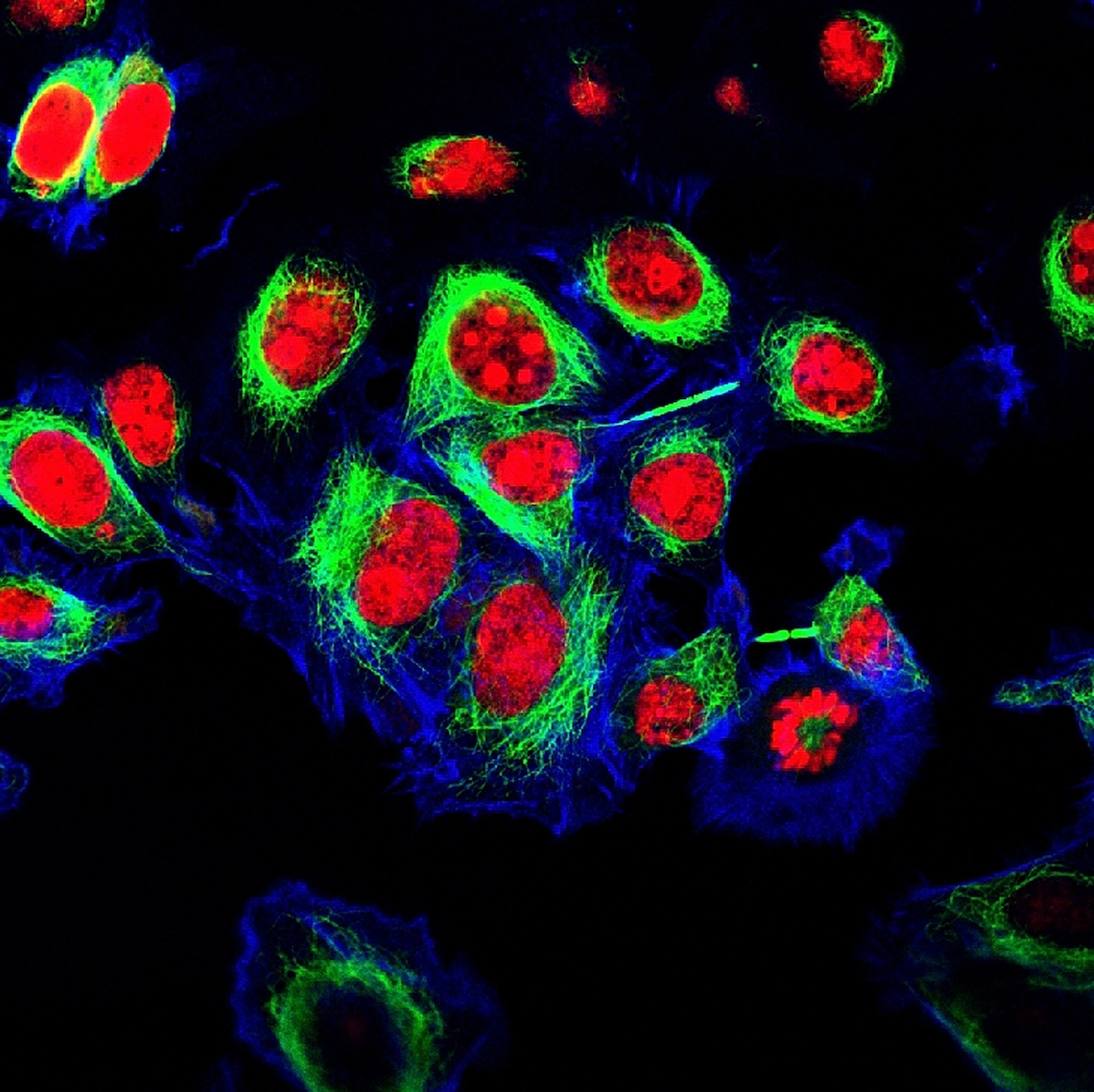 Epithelial cancer cells labeled with fluorescent molecules. Science journals strive to ensure such images are genuine.Credit: Vshivkova, Shutterstock
Epithelial cancer cells labeled with fluorescent molecules. Science journals strive to ensure such images are genuine.Credit: Vshivkova, Shutterstock"I use Imagetwin and Proofig to scan dozens of papers per day," says Bik. But, she says, she finds they throw up a lot of false positives. "I need to manually go over all the findings to ensure I am not making any false accusations."
The Black Spatula project is just starting out, with a community of contributors all exploring different ways that AI might be brought to bear on error checking. "It's still in the experimental phase, with multiple volunteers collaborating to try out different approaches," says Newman. Joaquin Gulloso, an independent technology researcher based in Cartagena, Colombia, is, for example, currently trying to lower any given false positive rate by feeding chatbots with more contextual information, such as the full text of the paper's references and supplementary information.
This is a relatively expensive task. Gulloso estimates it probably costs around $5 to do a thorough chatbot analysis of a 20-page paper; but if the user wants to encompass its references, that can easily balloon to over $200. The cost of AI is, however, dropping rapidly, Newman says: "We are optimizing for quality of analysis rather than cost, in the expectation that an analysis that costs $100 today will cost $1 in a year or two, and pennies the year after that." Such numbers are subject to a lot of uncertainty. Plenty of researchers caution that simple efforts to use chatbots to investigate papers for errors might flag a lot of small, inconsequential, or even completely-made-up mistakes that can be traced to AI hallucinations, leading to a high false positive rate and wild goose chases. Such systems can be "just a waste of a lot of people's time and energy," says Nick Brown of Linnaeus University, in Sweden.
The pro is you're gonna find more cases. The con is you're gonna find more cases.
- Ivan Oransky
False positives are more problematic for some users than others. A high false positive rate would be catastrophic for mass scans of the literature, says Newman: "It would be an enormous project to manually separate the wheat from the chaff." But it might be acceptable for someone checking their own paper, since wading through a few false flags to find a real one is probably worth their time, Brown adds.
It's still too early to say how useful big-picture chatbot paper screeners might prove. "I say if AI can help find problems in papers, then great," says Oransky. But as for doing this at scale, he adds, "The pro is you're gonna find more cases. The con is you're gonna find more cases." Flooding the internet with hundreds of thousands of potential problems is a problem. "At best, it dilutes real messaging and real findings. At worst it makes things impossible," Oransky says.
The Problems with Peer Review
Ivan Oransky of Retraction Watch and arXiv discusses whether science publishing is broken.
Full Podcast
There are plenty of other potential issues. Since it is often unclear what information generative AI is using to come to a given conclusion, for example, it's possible that bots might erroneously learn to be more distrustful of some work based on inequitable criteria. "If you have these models deciding if things are problematic, they might reinforce certain biases, such as flagging papers more from certain countries," says Nuijten. Editors might become predisposed to rejecting out of hand any papers red-flagged by bots to save time, she adds, even if those red flags are irrelevant, biased or wrong.
Other issues surround copyright and privacy. Many journals
won't allow reviewers or editors to feed pre-publication manuscripts into a public-facing chatbot like ChatGPT, since that adds sensitive knowledge into a chatbot's training dataset, which might leak out in other chats. It is possible to have localized or specialized AI tools that avoid this problem.
Nuijten, like many others, can see a future where journals simply use an in-house chatbot as one of their peer reviewers. "I think that's a very likely thing to happen," she says. But she'd prefer to see a system where AI reviewers are limited to simpler checklist issues, and where journal editors are trained to take that advice with a grain of salt.
Lumb says AI is being integrated across the entire science landscape. "You see it in peer review, in research discovery, all across the workflow," he says. "New ideas are going to come quickly."
Lead image credit: Galeanu Mihai, iStock